2023. 12. 14. 10:39ㆍ공부/딥러닝
Transformer 기술 조사
- 논문 : Attention is All You Need(Ashish Vaswan, Noam Shazeer,Niki Parmar, ... 2017)
- Transformer은 2017년 구글에서 발표한 상기 논문에서 나온 모델로 seq2seq 구조인 인코더-디코더를 따르면서도, 논문의 이름과 동일하게 Attention 만으로 구현된 모델임. 본 모델은 RNN, CNN 등 을 전혀 사용하지 않고 인코더-디코더 구조를 설계하였음에도 RNN 보다 우수한 성능을 보임
- 기존에 사용되었던 seq2seq 구조는 인코더-디코더 구조로 구성되어 있으며, seq2seq 모델에서는 인코더가 입력 시퀀스를 하나의 벡터로 압축을 하여 디코더에서 벡터를 출력 시퀀스로 만들어주었다. 이러한 구조는 인코더에서 압축되는 과정에서 시퀀스 정보가 손실된다는 단점이 있다. Attention은 손실되는 값을 보정하기 위해 사용되었다.

- encoder의 hidden state을 적절한 값으로 초기화
- Time step 마다 단어(token)가 입력되면 인코더에서 hidden state을 업데이트
- Input sequence의 마지막까지 이 과정을 반복하여 encoder의 최종 hidden state는 Input sequence의 압축된 정보를 담게 된다
- ③의 마지막 시점의 encoder hidden state를 문맥 벡터(context vector)라고 하며, context vector 값이 decoder로 전송
- decoder는 전달받은 context vector로 hidden state를 초기화 한다
- Time step(매 시점) 바로 직전 시점에 출력되었던 단어를 입력받아 hidden state로 업데이트
- 마지막 <eos> token이 출력될 때 까지 ⑥번 과정 수행한다

- "ABC" 가 인코더에서 처리되고 디코더에서 출력문장으로 "WXYZ"를 생성하는 구조이다. 인코더에서 입력문장의 모든 단어들을 순차적으로 입력받은 뒤 마지막에 "ABC"를 압축하여 하나의 벡터로 만드는 "컨텍스트 벡터(context vector)" 과정 후 압축된 컨텍스트 벡터는 디코더로 전송되어 번역된 단어를 한 개씩 순차적으로 출력한다.
- Seq2Seq 이전 모델들도 이전 입력을 고려하는 것이 가능하였다. 하지만 RNN은 짧은 윈도우 크기(Shorter Reference Window)를 가지고 있기 때문에 Input이 길어지면 주어진 Sequence 길이보다 긴 입력을 고려하지 못한다는 문제를 가지고 있었다.
- 또한, 구조상 순차적으로 Input을 처리해야 되었기에 병렬화가 불가능하였다. 그렇기 때문에 대규모의 데이터셋의 경우 학습 시간이 지나치게 길어지고 학습 및 추론의 속도가 느린 문제를 가지고 있었다.
- 그리고 Input sequence의 길이가 길 경우 앞부분의 정보가 뒤쪽 정보에 영향을 미치는 경우에 관련된 정보를 잘 학습하지 못하는 문제가 있었다.
- Window의 size가 고정되어 있어 sequence에서 멀리 떨어진 항목들 간의 관계성은 Gradient Vanishing 문제로 학습이 잘 되지 않았다.

Attention Mechanism(어텐션 메커니즘)은 병렬화 문제, Long Distance Dependacy 문제를 해결할 수 있는 해결책으로 접근되었다. RNN에 비해 LSTM, GRU 등은 상대적으로 긴 Window size를 가졌지만 이 크기는 무한하지 않기 때문에 한계가있었다. Attention Mechanism(어텐션 메커니즘)은 이론적으로 Compute Resource가 충분하다는 가정하에 무한한 크기의 Window size를 가질 수 있으며, 긴 Sequence에도 담고 있는 전체적인 문맥을 반영할 수 있었다.
또한, 병렬화가 가능하고 각 Query가 모든 Key를 비교하여 Long Distance Dependency 문제를 해결할 수 있었으며, 학습 속도가 상대적으로 빠르고 더 큰 데이터셋에도 적용이 가능하였다. Transformer 모델의 강점으로 Input의 길이와 상관없이 중요한 모든 부분에 "Attend" 할 수 있게 만들어진 모델이다.

- Transformer 의 모델 아키텍처로 셀프 어텐션(Self-Attention)은 같은 문장 내에서, 입력으로 들어온 시퀀스 안에서 단어들간의 관계를 고려한다. Encoder에선 Self-attention과 Feed Foward Neural Network를 수행하며, Transformer 이전에 Input value를 embedding 작업을 거친다. 각 각의 Input 단어는 embed 차원의 각 원소마다 continous한 값을 가진 vector로 표현된다. (참고 사이트)

- Self-attention의 경로들은 다른 Input 값들에 의존적이며, Input word는 특정 수의 벡터로 표현되어 첫번째 Self-attention은 각 단어를 그에 맞는 벡터를 각각 찾아준다. Self-attention에서 하나의 단어를 벡터로 만들때, 각 한단어만을 벡터로 만드는 것이 아니라 자신을 포함한 다른 N개의 단어의 벡터도 같이 활용된다. 그리고 나머지도 단어들도 동일하게 적용되기 때문에 Input size가 길어질때마다 계산을 많이 필요로 하여 더 많은 메모리를 필요로 한다
- Input sequence의 모든 토큰과 토큰 사이의 관계를 계산하기 때문에, Input sequence의 길이가 길어지면 계산해야 할 연산수가 증가하고 메모리 요구사항도 증가한다. 이러한 한계점을 극복하기 위해 self-attention 가중치를 희소화하거나 self-attention 범위를 제한하여 메모리 요구사항을 줄이는 기법들 또한 개발되고 있다.
Transformer의 한계를 극복한 모델로는 다음과 같은 것들이 있습니다.
- Sparse attention : self-attention의 가중치를 희소화하여 메모리 요구 사항을 줄이는 기법입니다.
- Local attention : self-attention의 범위를 제한하여 메모리 요구 사항을 줄이는 기법입니다.
- Transformer-XL : 자기 순환적 self-attention을 사용하여 input size가 길어지더라도 무한한 윈도우 사이즈를 갖고 encoder-decoder을 처리하는 기법입니다.
Transformer-XL은 자기 순환적 self-attention을 사용하여 self-attention의 범위를 제한하지 않고, 입력 시퀀스의 모든 토큰 사이의 관계를 계산할 수 있습니다. 또한, self-attention의 가중치를 희소화하여 메모리 요구 사항을 줄일 수 있습니다.
따라서, Transformer-XL은 input size가 길어져도 메모리 요구 사항을 증가시키지 않고, 성능을 유지할 수 있는 모델입니다.
- Input에서 embedding된 벡터가 query, key, value를 하나만 사용하는 것이 아닌 여러개를 사용하여 enmbedding vector 차원 N개를 동일한 크기의 차원으로 나누어 각 크기의 embedding vector에 관해 각 head에 대응되는 query, key, value를 생성해 각 head 마다 scale dot product attention을 진행한다.
- 예를 들어 1024 사이즈를 가진 embedding vector에 8개의 multi-head를 가지고 attention 작업이 수행될 때, 1024 / 8로 128 크기로 입력의 embedding vector을 나누어 각각의 대응되는 query, key, value를 생성하여 8개의 head마다 scale dot product attention을 수행한다.

- 그리고 Transformer는 Input sequence의 순서 정보를 지니지 않아, 순서 또는 위치에 관한 정보를 부여하고자 Input에 위치 정보를 더하여 단어간 관계에 정의에 있어 어떠한 단어인지 알 수 있는 위치 정보를 더한다.
- Positional encoding은 Input sequence의 순서 정보를 고려할 수 있고, Transformer의 성능을 향상시킬 수 있는 역할을 함으로 모델 성능을 위해 효과적으로 사용하는 것이 중요하다.

- Transformer의 핵심은 RNN, CNN을 전혀 사용하지 않고 Positional Encoding을 사용하여 입력값의 위치 등을 판단한다. Self-attention을 통해 Attention score는 입력 문장에서 각 단어가 다른 단어들과의 연관성이 높은지를 계산하여 연관성을 알 수 있고, Positional Encoding을 통해 비교하고자 하는 단어의 위치에서 어느 위치의 단어와 연관성이 높은지를 알 수 있다.

- Self-Attention 수식으로 Value와 Querk, Key의 내적에 대한 Softmax를 취한 Attention score을 내적하여 Context Vector로 사용된다. Multihead-attention은 이러한 여러개의 Self-attention-layer 들을 총합한 것을 말하며, 무수히 많은 word vector의 수에 대해 가장 적합하고 높은 확률값을 가진 output이 생성될 수 있도록 대응되는 기법이다. 해결하고자 하는 문제에 맞게 사용될 Head의 수를 정해야하고 원하는 출력 크기를 갖추게 된다.
- Transformer은 GPT-3, BERT와 같은 NLP 모델의 기반이 되었고 NLP 뿐만 아닌 딥러닝 연구 분과에 적용되어 많은 혁신을 가져왔다. Transformer 구조를 기반으로 LLM은 계속해서 성장중이고 Language Model 뿐만 아닌 딥러닝 전체 분야에서 혁신을 가져오고 있다.
GPT 개발 동향
- 2017년 구글에서 발표된 "Attention is all you need" 에서 소개된 트랜스포머(Transformer) 모델은 RNN, CNN은 전혀 사용되지 않고 인코더와 디코더로 구성된 Attention 과정을 반복해 자연어 처리(NLP, Natural Language Processing) 분야의 혁신적인 발전을 가져옴과 동시에 GPT와 같은 대화형 인공지능 모델의 발전에 큰 도움을 주었다.
- GPT-1(Improving Language Understanding by Generative Pre-Training) 은 2018년 OpenAI에서 발표되었으며, 논문에서 언급되는 바로는 언어를 다양한 미분류된 말뭉치로 생성적 사전학습(Generative pre-training)을 진행하고, 그 후 특정 과정에 맞게 Fine-tunning(미세조정) 과정을 거쳐 성능 향상을 도모할 수 있다. 이전의 연구 접근법과는 달리 모델의 구조를 최소한으로 변화시키면서 효과적인 transfer(전이)를 얻기 위해 Fine-tunning(미세조정) 단계에서 Input representations를 각 과제에 맞게 사용하여 이러한 접근법이 다양한 Task에서 효과적임을 보인다고 언급한다.
- 본 논문에서 제시한 방법으로 과제에 대한 지식, 분류가 없는 task-agnostic 모델은 특정 과제에 특화된 구조를 사용 하는 모델의 성능을 뛰어넘는데 연구된 12개의 과제 중 9개에서 state-of-the-art 를 달성하는 결과를 보였다.
- GPT에서 말하는 핵심은 Unlbaeled된 text corpus(말뭉치)에서 모델을 Pre-training하고 해당 Task에 맞게 Fine-tuning하여 성과를 얻고자 하였다. [비지도 pre-traing]에 [지도 fine-tuning] 방법으로 <semi-supervise> 접근을 사용하였다.
- GPT-1 에서는 GLUE NLP 이해모델 벤치마크 평가지표를 사용하였다

- GPT-2(Language Models are Unsupervised Multitask Learners) 는 Fine-tuning 없이 적용되었으며 기존 방식이었던 semi-supervised learning인 비지도 pre-train에 지도 fine-tuning 방법이 아니라 지도 학습 자체가 없이 만들어 진다면 범용적으로 사용할 수 있을 것이라는 전제를 갖고 개발되었다.
- 이러한 이유는 학습되지 않은 데이터의 대응, 범용적이지 못하는 성능때문에 지도학습이 되지 않았다면 좀 더 범용적으로 사용이 가능하지 않을까 라는 생각에서 일반적이고 범용적인 모델을 구축하고자 하였다. 이는 Training dataset에 라벨링을 할 필요가 없어 비용(시간, 인건비 등)을 절약할 수 있었다.
- GPT모델이 계속해서 발전해오며 성능이 월등히 발전할 수 있었던 이유는 학습 매개변수의 증가에 따라 조건부 확률 예측 성능이 급격히 좋아지게 되었다.
- GPT 1(2018) : 약 1억 1700만개
- GPT 2(2018) : 약 15억개 (이전 대비 10배 증가) -> 매개변수의 증가로 인간과 유사한 수준의 글쓰기 가능, 책 한페이 작성에 약 10초 소요됨)
- GPT 3(2020) : 약 1,750억개 (GPT1에 비해 약 1000배, GPT2에 비해 약 110배) -> 엄청난 수의 학습 매개변수로 다양한 언어, 연산, 글 생성, 코딩, 번역 등 다양한 분야에서 추론 성능이 좋아짐
- GPT 3.5(2022~) : GPT4 전의 버전으로 매개변수는 거의 동일하지만 생성형 모델의 문제인 잘못된 답변, 답변에 대한 오류, 전문 분야에 대해 추론이 가능하고 프로그래밍 개발 또한 가능한 수준까지 발전
- GPT 4(2023) : 매개변수 규모는 공개되지는 않았지만 약 5,000억개 이상으로 추정되며 GPT 3.5 모델에 비해 크게 개선되었다고 OpenAI에서 밝혔다.
- 2022년 11월 OpenAI는 ChatGPT를 대중에게 공개하며 LLM의 시장에 대한 관심이 증대되게 되었다. 모든 사람들이 GPT를 경험하며 새로운 언어모델들이 계속해서 개발되어지고 있으며, 다중언어 모델 개발은 인공지능 분야에서의 중요한 연구주제로 자리매김되었다.
- LLM의 연구는 다양한 언어를 이해하고 생성하는 인공지능 모델을 개발하는 것을 목표로 하며, 이를 통해 언어 장벽을 극복하고 전 세계 사람들이 보다 원활하게 소통할 수 있게 한다. 이러한 연구 목표를 가지고 많은 연구기관에서는 다국어 모델을 개발하고 있으며, 영어권에서는 활발히 모델 학습데이터를 생산하고 있다. 하지만, 비영어권 언어를 다루는 연구자들은 단일 언어 모델을 확보해나가고 있는 추세로 공개되어 있는 다국어 모델 학습 데이터 대부분은 영어에 편중되어 있어 비영어권 언어 Task에서는 좋지 못한 성능을 보이기 때문이다.
- 영어권에 편중되어 있는 다국어 언어모델인 BLOOM, XGLM 등은 영어 코퍼스의 비중이 30%, 49% 정도의 비중을 보이며 다국어 거대 언어 모델 프로젝트로 Polyglot을 시작으로 비영어권 언어 모델들이 개발되고 있다. Polyglot-ko는 TuNiB에서 수집한 1.2TB 규모의 한국어로 학습되었으며 공개된 모델의 크기는 1.2B, 3.8B, 5.8B, 12.8B로 총 네가지의 한국어 모델이 공개되었다.
LLM 동향
최근 인공지능(AI) 기술의 발전과 함께 챗봇(chatbot)을 비롯한 다양한 언어 기반 서비스에 혁신적인 변화를 가져오고 있다. 특히, 딥러닝 모델인 GPT(Generative Pretrained Transformer) 등의 등장으로 챗봇은 단순한 스크립트 기반 대화에서 벗어나 더욱 복잡하고 자연스러운 대화를 생성할 수 있게 되었다.
이러한 대형 언어 모델은 인공지능 기술의 한 분야로 자연어 처리 능력을 높여 효율성과 정확성을 향상시킬 수 있다.
특히 LLM은 문맥을 파악하고 상황에 맞는 답변을 생성해주는 능력을 갖추고 있어 다양한 산업에서도 활용성이 기대된다.
이러한 변화의 핵심에는 LLM(Large Language Model)은 방대한 양의 텍스트 데이터를 학습하여 다양한 언어 작업을 수행할 수 있는 인공지능 모델이 있다. 이러한 LLM 모델들은 텍스트 생성, 언어 번역, 질문 답변, 요약 등 다양한 분야에서 활용되고 있으며 성능과 범용성으로 주목받고 있고 대표적으로는 OpenAI의 GPT, Google의 Bard 등 이 있다.
OpenAI사의 GPT는 1,750개의 파라미터를 가진 대량의 텍스트 데이터 및 대화 형식을 통해 상호작용 하는 방식으로 훈련된 모델이다. 사용자의 질문에 대한 후속 질문을 답하거나, 잘못된 전제를 반박하거나, 부적절한 요청을 거부하는 등의 기능을 가지고 있다.
Google사의 Bard는 대화형 생성 인공지능 챗봇으로 초기에는 LaMDA 계열의 LLM에 기반하였고, 나중에는 PaLM LLM에 기반하였다. 또한 Bard는 소프트웨어 개발 작업에 도움을 줄 수 있는 코드 생성, 디버깅 및 코드 설명과 같은 기능을 제공한다.

GPT-3을 필두로 거대 파라미터 모델에 대규모 코퍼스(말뭉치)를 학습한 언어모델은 보다 자연스러운 문장을 생성하고 다양한 태스크를 작은 학습 데이터로도 수행하는 등의 가능성을 보였다. 이러한 긍정적 이슈에도 불구하고 빅테크 기업이 아닌 일반 기업, 연구자가 LLM 모델을 다루기에 어려운 이유는 학습에 막대한 자본이 필요, 데이터와 컴퓨팅 파워에 따른 기술 격차의 심화로 인해 다루기가 쉽지 않은 현실이다.
현재 많은 대형 IT 개발사에서는 대화형 생성 인공지능 챗봇인 LLM 모델을 개발하고있다. 이러한 모델들은 다양한 언어와 문화를 이해하고, 사용자의 요구에 따라 다양한 작업을 수행할 수 있다. 하지만, 현재까지는 영어를 기반으로 LLM 모델이 학습되었고 영어가 아닌 한국어로 질문을 할 경우 원하지 않는 답변이 생성되는 이슈가 존재한다.
이러한 상황에 변화를 가져오기 위해 HuggingFace가 중심이 되어 "거대 언어 모델의 민주화"를 위해 프로젝트가 진행되었으며, 전 세계 AI 연구자들이 다양한 언어를 포괄하는 176B 규모 언어모델 BLOOM을 2022년 7월 공개하였다.

BLOOM은 기존 유명 LLM 모델들에 필적하는 규모를 가졌으며, GPT-3보다 큰 1,760억 개의 파라미터를 가지고 있어 이러한 규모를 갖추고도 오픈소스로 공개, 특히 다국어 기반(Multi-lingual) 모델은 BLOOM이 최초로 공개되었다.
BLOOM은 46개의 언어 지원 뿐만 아니라 13개의 프로그래밍 언어를 지원한다. 계속해서 영어 위주로 발전을 해왔던 LLM은 자연스레 영어권이 아닌 다른 나라의 언어들이 배제될수 밖에 없었기 때문에 BLOOM은 다언어가 LLM 모델 발전에 영향을 주는 계기로 수많은 LLM 연구진에게 다양한 언어를 함께 학습할 수 있는 계기가 되었다.
한국에서는 네이버(NAVER)의 하이퍼클로바, 카카오(KAKAO)의 KoGPT 등 한국어를 base로 하는 모델들이 개발되어 서비스화 되고있다.


많은 국내 IT 기업에서 LLM 모델들을 개발중에 있으며, open AI의 GPT, Microsoft의 Bing, Google의 Bard에 비해 한국어에 대한 이해도가 가장 높고 Naver의 하이퍼클로바는 ChatGpt보다 6,500배 더 많은 한국어를 학습하였다.

LLM을 전문적으로 연구하는 많은 기업들에서도 한국어에 특화된 모델들을 개발하기위해 상업적 이용이 가능한 모델을 Fine-tuning하여 모델을 만들기 위해 한국어 데이터를 수집 및 정제, 가공하여 Full-fine tuning을 진행, 이렇게 LLM 연구가 활발히 이루어짐에 따라 영어의 기반인 모델을 한국어로 Finetuning 하여 모델들을 내놓고 있다.
다국어 모델은 mBERT, BLOOM, XGLM 등 다양한 다언어모델이 공개되었으며, 그 이후로도 다언어의 균형 잡힌 역량을 보여주는 대규모 언어모델인 Polyglot 이 개발 되고있다. Polyglot은 다언어 모델의 비영어권 성능에 문제가 있다는 것을 필두로 하여 영어 이외의 성능에 높은 다국어 모델을 재생산 하고자 Polyglot 모델 개발을 진행중이다.
mBERT
- BERT(Bidirectional Encoder Representations form Transformers)는 다양한 자연어 처리 분야에서 가장 좋은 성능을 내면서 여러가지 일들을 수행하는데 이용된다고 함
- BERT는 사전학습된 대용량의 레이블링 되지 않는 데이터를 이용하여 모델을 학습하고 이를 토대로 문서 분류, 질의 응답, 번역 등을 위한 신경망을 추가하는 전이학습 방법론이다.
- BERT multilingual base model은 MLM(Masked Language Modeling) 목표를 사용하여 가장 큰 Wikipedia를 갖춘 상위 104개 언어에 대해 Pretrain 된 모델이다.
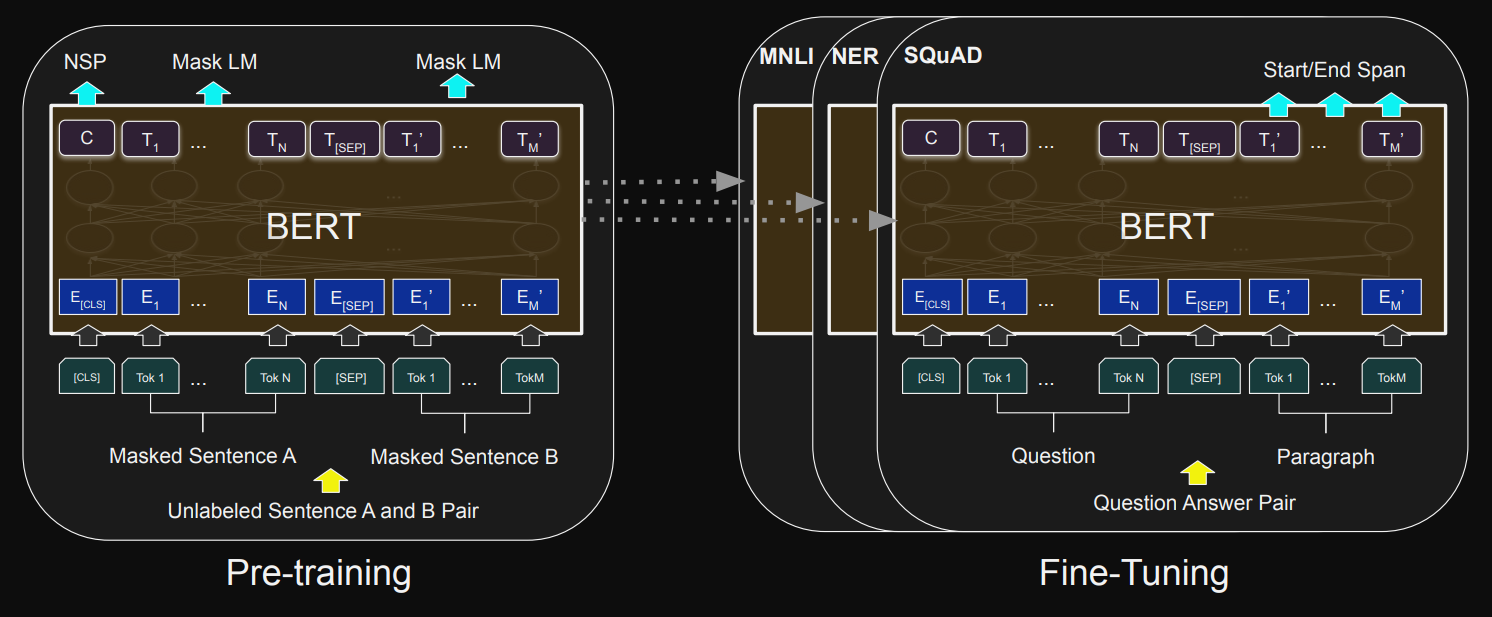
- 그림 1: BERT에 대한 전반적인 사전 훈련 및 미세 조정 절차. 출력 레이어 외에도 사전 학습과 미세 조정에 동일한 아키텍처가 사용됩니다. 동일한 사전 훈련된 모델 매개변수가 다양한 다운스트림 작업에 대한 모델을 초기화하는 데 사용됩니다. 미세 조정 중에는 모든 매개변수가 미세 조정됩니다. [CLS]는 모든 입력 예시 앞에 추가되는 특수 기호이고, [SEP]는 특수 구분 기호 토큰(예: 질문/답변 구분)입니다.
XGLM
- 다언어 자동 회귀 언어 모델로 30개의 다양한 언어로 구성된 균형 잡힌 Copus에서 훈련되었다. 본 모델은 총 564백만 개의 매개변수를 갖고 있으며, 총 5000억 개의 하위 토큰을 포함한다.
- 본 모델은 Few-shot Learning with Multilingual Language Models(2022)의 논문에서 소개되었으며 XGLM은 7.5억 개의 매개변수를 가진 모델로, 20개 이상의 언어에서 few-shot 학습에 있어서 새로운 최고 기록을 세웠다고 언급되었다.
- GPT-3과 비교했을때, 다언어 상식 추론에서 zero-shot 에서 +7.4%, 4-shot 에서 +9.4%의 정확도 향상을 보였으며, 자연어 추론에서는 각각 +5.4%의 향상을 보였다.

- 위 표에서 accuracy와 recall 점수 확인 가능하며, Bold체로 표시된 결과는 표에서 가장 높고, * 결과는 통계적으로 비교 가능한 다른 조건보다 훨씬 우수한 결과를 보인다.
- 흥미로운 결과로 대부분의 few-shot 결과가 zero-shot 보다 좋지 않은 결과를 보이는데, 이는 접두사를 사용하면 언어 모델이 예제를 사용할 수 없음을 나타냄
Polyglot
- Eleuther AI에서 개발한 다국어 언어 모델 프로젝트로 다양한 다국어 모델들이 이미 존재함에도 불구하고, 비영어 언어 성능에 불만족을 해결하기 위해 새로운 다국어 모델을 만들고자 하는 목표를 가지고 'Polyglot' 이라는 이름으로 다언어 모델이 탄생되었다.
- 하지만, Polyglot 한국어 모델은 다국어가 아니며 그 이유는 TUNiB에서 수집된 1.2TB의 한국어가 데이터가 있었기 때문에 보유하고 있는 한국어 데이터셋으로 한국어 모델을 만들었다.
- 1.2TB의 한국어 언어 데이터는 정제 후 863GB의 데이터셋으로 학습되었으며 해당 데이터셋은 Polyglot-ko 모델 학습을 위해 수집되었기 때문에 모델 공개를 위해 데이터셋은 공개되지 않았다.
- 공개된 Polyglot-ko 모델은 1.3B, 3.8b, 5.8b, 12.8b 로 4가지 모델 전부 오픈소스로 공개되어 학습, 추론으로 사용 가능
- Polyglot 모델은 다언어 모델을 목표로 개발되고자 하였지만, 실제로는 한국어 데이터셋으로 훈련된 Polyglot-ko 모델이 먼저 개발되었으며, 이러한 이유로는 한국어 모델이 기존의 다국어 모델과 성능을 비교하는데 도움이 되었고 이후 Polyglot-ko 모델을 기반으로 여러 한국어 LLM 모델들이 개발될 수 있는 근간이 마련되었다.
- Polyglot 모델 데이터셋은 TUNiB에서 선별된 대규모 데이터셋인 블로그, 뉴스, 말뭉치, AI-Hub 등 에서 데이터셋을 수집하였고 블로그 데이터 비율이 682GB로 전체 데이터셋 비율에서 60% 이상을 차지하여 추론 결과 확인 시 블로그 답변 형태를 많이 보이는 것을 확인할 수 있었다.

- Polyglot 모델은 훈련 후 추론 과정에서 문제를 줄이기 위해 개인정보, 반복되는 단어 및 문자, 중복된 인스턴스 등을 배제하고자 하였고 이로 인해 주로 블로그 데이터, 뉴스 데이터 등이 주로 구성되었다. 또한, 블로그, 뉴스 등의 데이터에서 훈련에 상황 정보가 필요한 데이터, 짧은 텍스트 데이터는 배제되었다.
- 또한, 학습 품질에 문제가 될 수 있는 텍스트 데이터는 전처리 작업과정에 추가하여 모델 학습에 문제를 일으키지 않도록 구성하였다.
- 빈 텍스트 : 데이터 인스턴스에 텍스트가 없는 데이터
- 불필요한 공간 : 불필요한 데이터의 공백 등
- 비식별화 : 데이터의 개인 식별 정보가 비식별화 되지 않은 데이터
- 중복 : 중복된 데이터 인스턴스(중복 등)
- 정리되지 않은 HTML 태그 : HTML 태그 제거되지 않음
- 손상된 데이터 : HTML 또는 Markdown 일부만 존재하는 경우
- 짧은 텍스트 : 데이터 인스턴스가 너무 짧음
- 반복 문자 : 데이터에 반복되는 문자
- 특히, Polyglot 모델의 목적은 한국어 텍스트 생성이 중요하기 때문에 html과 같은 코드는 최대한 제거하였고 데이터 전처리에서 중요한 부분인 데이터의 길이는 학습 시 텍스트 길이가 길수록 모델 학습에 더 많은 맥락 정보를 포함할 수 있고, 텍스트 길이가 짧을수록 생성되는 맥락 정보는 작아진다.

- 상기 표는 Polyglot-ko 모델에 학습된 데이터세트의 토큰 길이 분포로 대부분의 텍스트 데이터 세트의 길이는 2000 토큰 미만으로 구성되어 있지만, 블로그, 뉴스 등 데이터 세트는 길이가 상대적으로 긴 것을 확인할 수 있다. 이러한 결과를 바탕으로 텍스트 길이에 대한 필터 조건을 설정할 수 있었고, 훈련 과정에서 모델이 블로그나 뉴스에 대한 정보의 문맥 정보를 가장 많이 학습한 것을 알 수 있다.
- 상기 모델로 추론 결과를 확인해보면, 질문에 대한 추론 시 블로그나 뉴스 등의 정보를 많이 담은 형태로 추론 결과를 도출해주는 것을 확인할 수 있다. 또한, 질문의 길이가 짧을 경우 모델이 추론 시 정확한 데이터를 출력해내지 못하며 질문의 의도를 정확히 파악하지 못해 전혀 다른 추론결과를 보여주는 결과를 가진다.
- 핵심 : Polyglot-ko 모델을 기반으로 Fine-tuning 하여 대화형 Polyglot 모델을 만들고자 함으로, 한국어 대화형 데이터셋을 구축하여 대화 데이터셋을 학습 후 대화의 문맥을 파악하며 그에 대해 추론한 결과를 보여주는 모델을 만들고자 한다.
KoAlpaca
- KoAlpaca는 Alpaca에서 공개한 데이터셋을 번역하고, ChatGPT로 답변을 생성하여 한국어 기반 데이터셋을 제작한 모델로 이 모델은 Alpaca 모델을 학습한 방식과 동일한 방식으로 학습을 진행하였다. 이들 모델들은 각각의 특성과 목표를 가지고 있지만, 공통적으로 다중언어를 이해하고 추론하는 것이 목표이다.
- Stanford Alpaca 모델 학습 방식과 동일한 학습 방식으로 학습을 진행하였고 KoAlpaca 모델의 백본 모델로 한국어 모델은 Polyglot-ko 모델을, 영어와 한국어 기반 모델은 LLAMA를 사용하였다.
- KoAlpaca 데이터셋은 Stanford Alapca에서 제공하는 5만 2천개의 데이터셋을 번역하여 사용되었으며, 기본적으로 Stanford Alpaca 데이터셋은 "instruction", "input", "output" 으로 구성되어져 있다
...
{
"instruction": "Describe a time when you had to make a difficult decision.",
"input": "",
"output": "I had to make a difficult decision when I was working as a project manager at a construction company. I was in charge of a project that needed to be completed by a certain date in order to meet the client\u2019s expectations. However, due to unexpected delays, we were not able to meet the deadline and so I had to make a difficult decision. I decided to extend the deadline, but I had to stretch the team\u2019s resources even further and increase the budget. Although it was a risky decision, I ultimately decided to go ahead with it to ensure that the project was completed on time and that the client\u2019s expectations were met. The project was eventually successfully completed and this was seen as a testament to my leadership and decision-making abilities."
},
{
"instruction": "Identify the odd one out.",
"input": "Twitter, Instagram, Telegram",
"output": "Telegram"
},
...- Stranford Alpaca의 데이터셋을 번역하여 데이터셋을 구축하였음.
- KoAlpaca1.1 데이터셋의 경우 기존 Alpaca 모델이 짧게 대답하는 경향, 맥락을 이해하지 못하는 경향을 개선하기 위해 1.1 Dataset이 제작되었다. 이는 네이버 지식인을 크롤링하여 만들어졌고, Batch Decoding 기법을 통해 gpt-3.5-turbo API를 통해 질문과 본문, 채택된 답변의 본문을 기반으로 새롭게 데이터셋을 생성하였다.
- KoAlpaca는 base 모델을 polyglot-ko와 LLAMA를 이용하였으며, 각 base 모델을 기반으로 Fine-tuning한 KoAlpaca 모델을 구축하였다.
Kullum(구름)
- KULLUM(Korea University Large Language Model)은 고려대학교 NLP & AI 연구실과 HIAI 연구소가 개발한 한국어 Large Language Model(LLM)이며 한국어 모델 뿐만 아니라, 데이터 셋까지 전면 공개하여 한국어 LLM 생태계에 기여하고자 하는 프로젝트이다.
- KULLUM(구름)은 Backbone-model로 Polyglot-ko를 사용하였으며 5.8b, 12.8b 두 모델을 공개하였다.
- 데이터셋은 GPT-4-LLM과 Vicuna 그리고 Databricks의 Dolly 데이터셋을 병합하였으며, 모든 데이터셋은 DeepL을 이용하여 한국어로 번역하였다. 또한, Polyglot 모델에 PEFT(Parameter-Efficent-Fine-Tuning)를 적용하여 학습을 진행하였다.
- Evaluation(평가)의 경우 대화 평가 메트릭 (Dialogue Evaluation Metric)을 사용하여 모델 간 한국어 대화를 평가하였고 여기에 사용된 평가 모델은 GPT-4를 사용하였다. GPT-4를 이용한 평가 방법으로 G-Eval: NLG Evaluation using GPT-4 with Better Human Alignment (Yang Liu. et. al. 2023) 과 USR: An Unsupervised and Reference Free Evaluation Metric for Dialog Generation (Shikib Mehri. et. al. 2020) 두가지를 활용하여 Prompt를 구성하였다.
- 이 평가 방법은 GPT-4에게 질문과 모델의 추론된 답변을 제공하고 Prompt단에서 이해가능성, 자연스러움, 맥락 유지, 흥미, 지시어 사용, 전반적 품질 등에 대한 점수를 산출하게 하는 방법론이다.
- Kullum은 GPT-3.5-Turbo, GPT-4, KoAlpaca, KoVicuna 모델과 비교를하여 G-Eval 점수를 평가하였으며, 해당 점수는 아래 그림과 같다.

두 사람 간의 대화가 주어집니다. 다음의 지시문(Instruction), 입력(Input)을 받게 될 것입니다. 그리고 지시문과 입력에 대한 응답(Response)이 제시됩니다.
당신의 작업은 응답을 평가 단계에 따라 응답을 평가하는 것입니다.
이 평가 기준을 꼼꼼히 읽고 이해하는 것이 중요합니다. 평가하는 동안 이 문서를 계속 열어두고 필요할 때 참조해 주세요.
평가 기준:
- 이해 가능성 (0 - 1): Input에 기반하여 Response를 이해 할 수 있나요?
- 자연스러움 (1 - 3): 사람이 자연스럽게 말할 법한 Instruction 인가요?
- 맥락 유지 (1 - 3): Input을 고려했을 때 Response가 맥락을 유지하나요?
- 흥미롭기 (1 - 3): Response가 지루한가요, 아니면 흥미로운가요?
- Instruction 사용 (0 - 1): Instruction에 기반하여 Response를 생성 했나요?
- 전반적인 품질 (1 - 5): 위의 답변을 바탕으로 이 발언의 전반적인 품질에 대한 인상은 어떤가요?
평가 단계:
1. Instruction, Input, 그리고 Response을 주의깊게 읽습니다.
2. 위의 평가 기준에 따라 Response을 평가합니다.
Instruction:
{{instruction}}
Input:
{{input}}
Response:
{{response}}
Result
- 이해 가능성 (0 - 1):
- 자연스러움 (1 - 3):
- 맥락 유지 (1 - 3):
- 흥미롭기 (1 - 3):
- Instruction 사용 (0 - 1):
- 전반적인 품질 (1 - 5):- GPT-4에게 주어지는 Prompt 내용은 위와 같으며, Fine-Tuning을 통해 생성된 모델에서 질문과 답변 데이터를 가지고 GPT-4에게 평가를 요청하는 형태이다.
- 해당 방법론은 "질문-답변"의 평가에 있어서 전반적으로 대화의 내용을 기반으로 점수를 산정하는 방식이다. 대화의 매끄러움, 자연스러움 등이 주 평가의 목적이며 질문에 대한 명확한 답을 하는 것이 목적이기 보다는 대화의 자연스러움이 중요한 평가이다.

- 하지만 1~5 척도의 문제로 소수 값이 아닌 정수 값만 출력을 하는 문제가 있어 텍스트 간의 미묘한 차이에 대한 평가 점수가 동일하게 발생하는 문제가 존재한다.
- 이러한 문제를 해결하기 위해 LLM 출력 토큰 확률 점수를 정규화하고 가중치 합계를 최종 결과로 도출하여 미리 정의된 점수 집합(1~5)이 주어지면 각 점수의 확률을 계산한다. 이 방법으로 텍스트 품질 다양성을 더 잘 반영할수 있는 점수를 얻을 수 있다.
- KULLUM은 평가 모델로 GPT-4를 이용하여 Evaluation을 진행하였고 여러 모델들과 비교하여 성능에 대한 결과를 시각화 하였다.
BenchMark - lm-evaluation-harness
- Polyglot 모델을 개발한 EleutherAI에서 모델의 성능을 평가하기위해 lm-evaluation-harness란 Language Model을 평가할 수 있는 모델을 개발하였다.
- 이는 NLP 모델을 Benchmark가 가능한 200개 이상의 모델을 집약해놓았으며, 각 목적에 맞게 Fine-tuning한 model을 평가 가능하다.
- 한국어 모델에서 대표적으로 benchmark로 많이 사용되는 KLUE, Kobest, Korquad, kohatespeech 등이 있으며 KLUE의 경우 8가지의 Task에 대한 Benchmark 테스트가 가능하다.
- KLUE는 대표적으로 MRC(기계독해), NLI(자연어 추론) 등의 Task가 있으며 해당 task를 이용하여 구축된 모델을 평가할 수 있다.
현재 대표적으로 가장 많이 알려지고 활용되는 모델은 Polyglot-ko 모델로 GPT-NeoX 모델을 base로 하여 Polyglot 모델이 생산되었다.
'공부 > 딥러닝' 카테고리의 다른 글
| [NLP]Polyglot finetuning 방법 / 토크나이저 정리 / huggingface 업로드관련 (0) | 2024.06.11 |
|---|---|
| [NLP]한국어 언어 모델 Polyglot 테스트 및 사용법 (0) | 2023.07.14 |
| [NLP]GPTNeo, KoAlpaca, Polyglot 한국어 모델 관련 이슈 및 세부스펙 정리 (0) | 2023.06.02 |